
- * 프린트는 Chrome에 최적화 되어있습니다. print
인공지능대학원 / Graduate School of Artificial Intelligence

김지수 Gi-Soo Kim
인공지능대학원 / Graduate School of Artificial Intelligence
 +82-52-217-3715
+82-52-217-3715 gisookim@unist.ac.kr
gisookim@unist.ac.kr https://sdm.unist.ac.kr
https://sdm.unist.ac.kr Bldg. 112 Rm. 302-4
Bldg. 112 Rm. 302-4
Curriculum Vitae
· Aug. 2020~Present: Assistant Professor, Ulsan National Institute of Science and Technology
· Mar. 2019~July. 2020: PostDoc, Seoul National University
Academic Credential
· Mar. 2013~Feb. 2019: Ph.D. in Statistics, Seoul National University
· Mar. 2008~Feb. 2013: B.Agr. in Food Science and Biotechnology and B.S. in Statistics, Seoul National University
Awards/Honors/Memberships
· Global Ph.D. Fellowship Grant (Mar. 2016 – Feb. 2019; grant awarded by National Research Foundation of
Korea to 200 Ph.D. candidates per year from all disciplines)
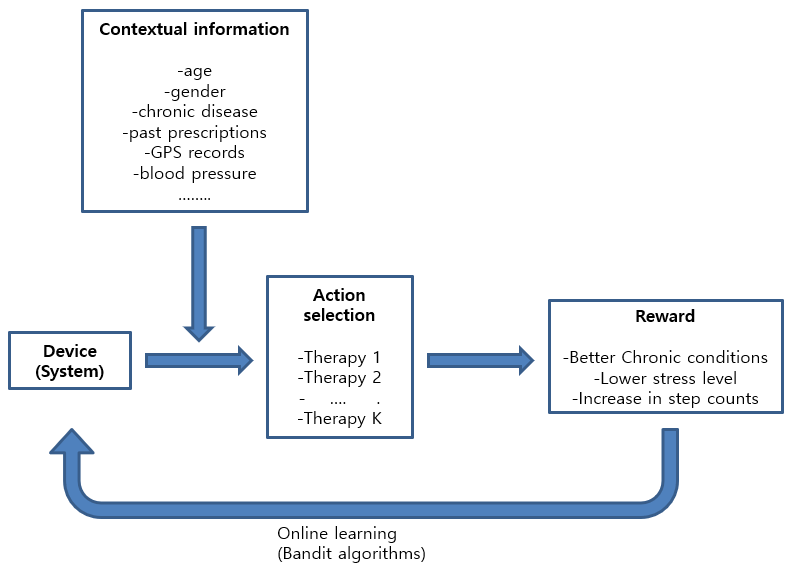
순차적 의사결정을 위한 다중 슬롯 머신 (multi-armed bandit) 을 연구합니다. 다중 슬롯 머신은 주어진 다수의 선택지 가운데 하나를 선택하고 보상을 받는 과정을 반복하면서 축적되는 정보로 보상 메커니즘를 학습하여 시간이 지남에 따라 최적의 선택지를 찾아가는 알고리즘입니다. 온라인 학습 방법론, 최적화 방법론 등을 활용하여 미지의 보상 모형을 효율적으로 학습하는 동시에 보상을 최대화하는 알고리즘을 개발하며 이론적 성능을 도출합니다. 또한 개발된 알고리즘을 뉴스 기사 추천 시스템, 전자 상거래 아이템 추천 시스템, 모바일 헬스 어플리케이션 등에 적용하는 프로젝트를 진행합니다. 이외에도 인과적 추론 방법을 활용하여 다중 슬롯 머신 알고리즘을 후 향적 (retrospective method) 으로 평가, 비교하는 연구도 진행합니다.
Our research interests are focused on statistical approaches to the sequential decision problem. The multi-armed bandit (MAB) problem formulates the sequential decision problem in which a learner is sequentially faced with a set of available actions, chooses an action, and receives a random reward in response. The actions are often described as the arms of a bandit slot machine. The act
of choosing an action is characterized as pulling an arm of the bandit machine, where different arms give possibly different rewards. By repeating the process of pulling arms and receiving rewards, the learner accumulates information about the reward compensation
mechanism and learns from it, choosing the arm that is close to optimal as time elapses. In our lab, we integrate online learning and optimization techniques to develop algorithms that efficiently learn the reward model while maximizing the rewards. We also apply the developed algorithms to real tasks such as recommendation systems and mobile health apps. We also use causal inference to evaluate the performance of multi-armed bandit algorithms in a retrospective way.
Major research field
Sequential Decision, Multi-armed bandit algorithms, Online learning, Causal inference, Policy evaluation
Desired field of research
Online learning
Research Keywords and Topics
Sequential Decision, Multi-armed bandit algorithms, Online learning, Causal inference, Policy evaluation, Causal inference, Missing data analysis
Research Publications
· Kim, G.S., Kim, J.P., Yang, H.J. Robust tests in online decision-making . Thirty-Sixth AAAI Conference on Artificial Intelligence (AAAI 2022).
· Kim, G.S., Paik, M.C. Doubly-robust Lasso bandit. Neural Information Processing Systems (NeurIPS 2019), 5877-5887, 2019.
· Kim, G.S., Paik, M.C. Contextual multi-armed bandit algorithm for semiparametric reward model. Proceedings of the 36th International Conference on Machine Learning (ICML 2019), 97:3389-3397, 2019.
Patents
· 다중 사용자에 대한 그래프 기반 상황별 다중 슬롯 머신 문제의 해를 산출하는 장치 및 방법, 백명희조, 백승훈, 최영근, 김지수, 2021년 8월.
METHOD AND DEVICE FOR REINFORCEMENT LEARNING USING NOVEL CENTERING OPERATION
· BASED ON PROBABILITY DISTRIBUTION (신규한 가중치를 이용한 센터링 연산을 적용한 강화 학습 방법 및 장치), 백명희조, 김지수, 2020년 3월.
국가과학기술표준분류
- EE. 정보/통신
- EE01. 정보이론
- EE0102. 알고리즘
국가기술지도분류
- 기타 분야
- 060000. 국가기술지도(NTRM) 99개 핵심기술 분류에 속하지 않는 기타 연구
녹색기술분류
- 녹색기술관련 과제 아님
- 녹색기술관련 과제 아님
- 999. 녹색기술 관련과제 아님
6T분류
- 기타 분야